엔티티들은 대부분 다른 엔티티와 연관관계를 가진다. 예를들면 회원과 주문이 있다고한다면, 회원은 회원 관련한 정보를 담고있고, 주문은 상품의 구매와 같은 정보를 담고 있을 것이다. 둘은 완전히 다른 특성을 가지고있는데, 서로다른 특성을 지닌 정보들끼리 관계를 맺게 해줄 수 있다. 상품구매를 누가했을까? 이렇듯 회원과 주문을 연결하여 관계를 맺는 것을 연관관계라고 한다.
연관관계 개념 및 이해
핵심 키워드
- Direction (방향)
단방향(둘 중 한쪽만 참조) 양방향(양쪽 모두 참조)이 있다. 방향은 객체관계에만 존재한다
- Multiplicity (다중성)
다대일(N:1), 일대다(1:N), 일대일(1:1), 다대다(N:M)
- owner (연관관계의 주인)
객체를 양방향 연관관계로 만들게 되면 연관관계의 주인을 정해야 한다

- 회원과 팀이 있다
- 회원은 하나의 팀에만 소속될 수 있다
- 회원과 팀은 다대일 관계다
- 객체 연관관계
회원 객체는 Member.team 필드(멤버변수)로 팀 객체와 연관관계를 맺는다
회원 객체와 팀 객체는 단방향 관계이다. 회원은 Member.team 필드를 통해서 팀을 알 수 있지만 반대로 회원을 알 수 없다.
- 테이블 연관관계
회원 테이블은 TEAM_ID 외래키로 팀 테이블과 연관관계를 맺는다
회원 테이블과 팀 테이블은 양방향 관계이다. MEMBER 테이블의 TEAM_ID FK를 통해 TEAM과 JOIN할 수 있고, 반대로도 JOIN이 가능하다.
=> 객체의 참조를 통한 연관관계는 단방향이다. 양방향 관계는 서로 다른 단방향 관계 2개가 합쳐져서 양방향이 된다.
=> 객체는 참조(주소)로 연관관계를 맺으며, 테이블은 외래키(FK)로 연관관계를 맺는다
- 객체 연관관계 예
@Getter
@Setter // lombok
public Class User {
private String userId;
private String userName;
private Group group; // Group의 참조를 보관
public void setGroup(Group group) {
this.group = group;
}
}
@Getter
@Setter
public class Group {
private String groupId;
private String groupName;
private String groupAddress;
}
// main
public static void main(String[] args) {
User user1 = new User("1", "이몽룡");
User user2 = new User("2", "성춘향");
Group group = new Group("234", "쾌걸춘향", "서울특별시 남원구 몽룡동 1번지");
user1.setGroup(group);
user2.setGroup(group);
Group findGroup = user1.getGroup();
}
- 테이블 연관관계 예
CREATE TABLE `USER` (
`USER_ID` VARCHAR(45) NOT NULL,
`USER_NAME` VARCHAR(255),
`GROUP_ID` VARCHAR(45),
PRIMARY KEY (`USER_ID`)
);
CREATE TABLE `GROUP` (
`GROUP_ID` VARCHAR(45) NOT NULL,
`GROUP_NAME` VARCHAR(255),
`GROUP_ADDRESS` VARCHAR(255)
PRIMARY KEY (`GROUP_ID`)
);
ALTER TABLE `USER` ADD CONSTRAINT `FK_USER_GROUP`
FOREIGN KEY (`GROUP_ID`)
REFERENCES `GROUP`
;데이터베이스에서는 JOIN을 통해 연관관계를 맺을 수 있다.
연관관계 매핑 어노테이션
@JoinColumn(name="GROUP_ID"): 외래키를 매핑.
| 속성 | 기능 | 기본값 |
| name | 매핑할 외래 키 이름 | 필드명 + _ + 참조하는 테이블의 기본 키 컬럼명 (group_GROUP_ID) |
| referencedColumnName | 외래 키가 참조하는 대상 테이블의 컬럼명 | 참조하는 테이블의 기본키 컬럼명 (GROUP_ID) |
@OneToOne: 일대일(1:1) 관계 매핑.
- 일대일 관계는 그 반대쪽도 일대인 관계다.
- 일대일 관계는 다대일(N:1)과는 다르게 두곳 중 어느 곳이나 외래 키를 가질 수 있다.
- 다대일처럼 한쪽에서 연관관계의 주인(mappedby)를 가져야한다.
@ManyToMany: 다대다(M:N) 관계 매핑.
- 관계형 데이터베이스는 테이블 2개로는 다대다 관계를 표현할 수 없으며, 중간 연결 테이블을 추가해야한다.
- 객체는 테이블과는 다르게 2개로 다대다 관계를 만들 수 있다.
- 다대일처럼 한쪽에서 연관관계의 주인(mappedby)를 가져야한다.
@Entity
public class User {
@Id
@Column(name = "USER_ID")
private String userId;
private String userName;
@ManyToMany
@JoinTable(
name = "USER_PRODUCT",
joinColumns = @JoinColumn(name = "USER_ID"),
inverseJoinColumns = @JoinColumn(name = "PRODUCT_ID")
)
private List<Product> products = new ArrayList<Product>();
}
// 단방향 Case
@Entity
public class Product {
@Id
@Column(name = "PRODUCT_ID")
private String productId;
private String productName;
}
// 양방향 Case
public class Product {
@Id
@Column(name = "PRODUCT_ID")
private String productId;
@ManyToMany(mappedby = "products") // 역방향 추가. (외래키 관리 테이블의 참조 필드변수)
private List<User> users;
}
- @ManyToMany 다대다 매핑시, @JoinTable 속성값
| 속성 | 기능 |
| name | 연결 테이블을 지정한다. |
| joinColumns | 현재 객체에서 다대다로 매핑할 필드명을 지정한다. |
| inverseJoinColumns | 반대편 객체에서 다대다로 매핑할 필드명을 지정한다. |
- 연결 테이블의 한계점과 해결방법
@Entity
@IdClass(UserProduct.class)
public class UserProduct implements Serializable {
@Id
@ManyToOne
@JoinColumn(name = "USER_ID")
private User user; // UserProduct의 userId와 연결
@Id
@ManyToOne
@JoinColumn(name = "PRODUCT_ID")
private Product product; // UserProduct의 productId와 연결
private int orderAmount;
private LocalDateTime orderDateTime;
@Override
public boolean equals(Object o) {
return super.equals(o);
}
@Override
public int hashCode() {
return super.hashCode();
}
}- 식별자 클래스(@IdClass)를 만들어 복합키를 생성하는 방법으로 해결할 수 있다.
-> 이렇게 되면, 연결테이블에 필드를 추가할 수 있게 된다.
- Serializable을 구현해야하며, equals()와 hashCode()를 구현해야 한다.
- Class 접근제어자가 public 이어야하며, 기본 생성자가 있어야 한다.
=> 가장깔끔한 방법은 연결테이블 역할을 하면서 고유의 역할을 하는 테이블로 정의하여 새로운 기본키를 사용하는 방식이다. 이경우, 이 테이블은 다른 테이블과 다대일(N:1)관계로 매핑해주면 된다.
@ManyToOne: 다대일(N:1) 관계 매핑.
| 속성 | 기능 | 기본값 |
| optional | 연관관계의 선택여부 (false인경우 필수로 있어야함) | true |
| fetch | 글로벌 페치 전략 설정 | - @ManyToOne=FetchType.EAGER - @OneToMany=FetchType.LAZY |
| cascade | 영속성 전이 기능 | |
| targetEntity | 연관된 엔티티의 타입 정보를 설정 (거의 사용하지 않음) |
연관관계 사용 예제
public class RelationShip {
// 저장
public void my_save() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("save");
EntityManager em = emf.createEntityManager();
// 그룹1 저장
Group group1 = new Group("1", "그룹1", "서울특별시 행복구 감사동");
em.persist(user1);
// 회원1 저장
User user1 = new User("1", "사람1");
user1.setGroup(group1); // 연관관계 설정 user1 -> group1
em.persist(user1);
// 회원2 저장
User user2 = new User("2", "사람2");
user1.setGroup(group1); // 연관관계 설정 user2 -> group1
em.persist(user2);
}
// 조회
public void my_list() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("list");
EntityManager em = emf.createEntityManager();
User user1 = em.find(User.class, "1");
Group group1 = user1.getGroup(); // 객체 그래프 탐색
}
// 수정
public void my_update() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("update");
EntityManager em = emf.createEntityManager();
Group group2 = new Group("1", "그룹2", "서울특별시 행복구 싫어동");
em.persist(group2);
// 회원1에 새로운 그룹2 변경
User user1 = em.find(User.class, "1");
user1.setGroup(group2);
}
// 삭제
public void my_delete() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("delete");
EntityManager em = emf.createEntityManager();
User user2 = em.find(User.class, "2");
user2.setGroup(null); // 연관관계 제거
em.remove(user2); // 회원 삭제
}
}양방향 연관관계
Group에서 1:N관계와 mappedBy(연관관계의 주인 설정 / 아래에서 설명)를 통해 User와 매핑을 하여 양방향 연관관계 매핑을 완료하였다
@Getter
@Setter
// 그룹
public class Group {
@Id
@Column(name="GROUP_ID")
private String groupId;
private String groupName;
private String groupAddress;
// -- 추가 --
@OneToMany(mappedBy = "group")
private List<User> users = new ArrayList<User>();
}
@Getter
@Setter
// 회원
public class User {
@Id
@Column(name="USER_ID")
private String userId;
private String userName;
// -- 추가 --
@ManyToOne
@JoinColumn(name="GROUP_ID")
private String groupId;
}연관관계의 주인
위의 예제를 기준으로 했을때 User와 Group 엔티티가 각각 단방향으로 @ManyToOne, @OneToMany를 통해 매핑을 진행했으며 양방향 연관관계를 진행했다. 이때 객체의 참조는 둘인데 외래키는 하나이다. 결국 둘 사이에 차이가 발생하며, 두 객체 연관관계 중 하나를 정해서 테이블의 외래키를 관리해야하는데 이것을 연관관계의 주인이라고 한다.
- 연관관계를 주인을 정할 때는 mappedBy 속성을 사용한다
- 주인은 mappedBy 속성을 사용하지 않는다
- 주인이 아니면 mappedBy 속성을 사용해서 속성의 값으로 연관관계의 주인을 지정해야 한다
- 이러한 행위는 외래 키 관리자를 선택한다고도 한다
(!) 헷깔린다면.. 연관관계의 주인은 항상 다 쪽이 외래키를 가진다고 외우자. 따라서 @ManyToOne은 항상 연관관계의 주인이 되어서 mappedBy 속성을 설정할 수 없다.
group1.getUsers().add(user1);
group1.getUsers().add(user2);
// 주인이 아닌 객체가 저장을 시도했을때.. 무시됨.. (연관관계의 주인이 아니라서)
user1.setGroup(group1);
user2.setGroup(group2);
// 연관관계 설정(주인)=> 하지만 객체입장에서는 양쪽에서 위처럼 각각 관계를 맺어주는 것이 맞다. 주인이 아닌곳에서 관계를 맺을경우 저장은 진행되지 않지만 객체입장을 고려하여 양쪽에서 관계를 맺어주도록 하자.
// 최종코드
public class User {
private Group group;
public void setGroup(Group group) {
if (this.group != null) {
this.group.getUsers().remove(this);
}
this.group = group;
group.getUsers().add(this);
}
}this.group != null로 기존 객체 관계가 해제되지 않는 버그가 있기 때문에 추가로 작성되었다.
프록시
: 객체는 객체 그래프로 연관된 객체들을 탐색한다. 그런데 객체가 데이터베이스에 저장되어서 객체를 마음껏 조회하는 일은 부담스럽다. 이 문제를 해결하기 위해 JPA는 프록시(Proxy)기술을 사용한다. 프록시는 연관된 객체를 처음부터 데이터베이스에서 조회하는 것이 아닌, 실제 사용하는 시점에 데이터베이스에서 조회(지연로딩)할 수 있도록 한다.
User와 Group을 예로들어 설명
EntityManagerFactory emf = Persistence.createEntityManagerFactory("get");
EntityManager em = emf.createEntityManager();
User user1 = em.find(User.class, "1");
System.out.println(user1.getUserName()); // 회원의 이름을 조회하여 출력
// 엔티티를 실제 사용하는 시점까지 데이터베이스 조회를 미룸
User user2 = em.getReference(User.class, "1");User는 Group과 연관관계를 하고있다. 예제코드에서 find() User정보를 가져올 때 Group정보도 같이 가져오게될 것이다. 그런데 Group관련 정보는 사실 필요가 없다. JPA는 이런 문제점을 해결하기위해 엔티티가 실제 사용될 때까지(Group) 데이터베이스 조회를 지연하는 방법을 제공하는데 이를 지연 로딩이라고 한다. 그리고 이 지연 로딩기능을 사용하려면 실제 엔티티 객체 대신에 데이터베이스 조회를 지연할 수 있는 가짜 객체가 필요한데 이를 프록시 객체라고 한다.
- getReference()를 호출하면 JPA는 데이터베이스를 조회하지 않고 실제 엔티티 객체도 생성하지 않으며, 데이터베이스 접근을 위임한 프록시 객체를 반환한다.
- 프록시 클래스는 실제 클래스를 상속 받아서 만들어지므로 모양이 같다.
- user2.getUserName() 호출시, 실제 사용해야하므로 데이터베이스를 조회해서 실제 엔티티 객체를 생성하는데 이를 프록시 객체의 초기화라고 한다
- 프록시 객체의 초기화 모델
1] user2.getUserName()을 호출하여 실제 데이터를 조회
2] 프록시 객체는 실제 엔티티가 생성되어 있지 않아, 영속성 컨텍스트에 실제 엔티티 생성을 요청 (초기화)
3] 영속성 컨텍스트는 데이터베이스를 조회해서 실제 엔티티 객체를 생성
4] 프록시 객체는 생성된 실제 엔티티 객체의 참조를 멤버변수에 보관한다
5] 프록시 객체는 실제 엔티티 객체를 반환
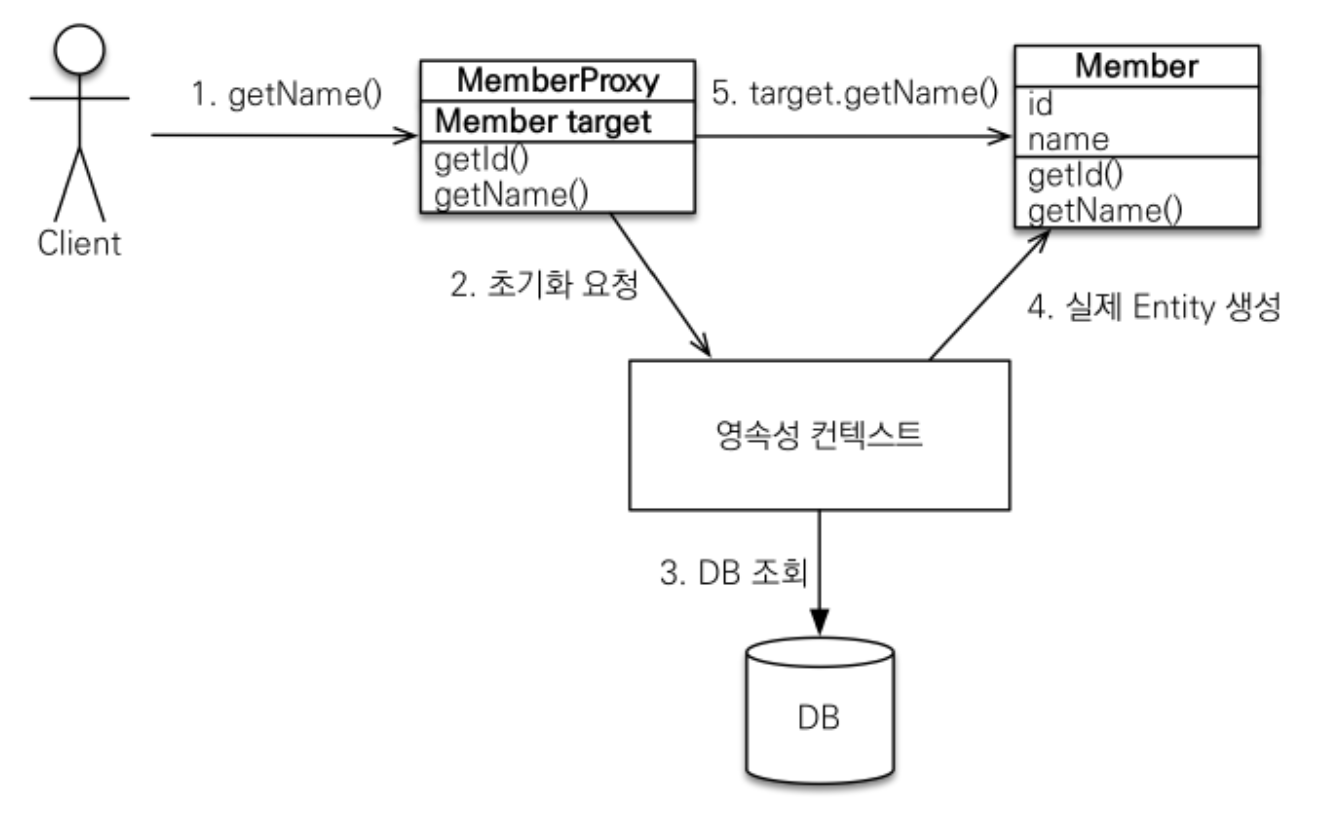
프록시의 특징
- 프록시 객체는 처음 사용할 때 한번만 초기화한다
- 초기화시 프록시 객체가 실제 객체로 바뀌는게 아닌 프록시 객체를 통해 실제 엔티티에 접근하는 것이다.
- 프록시 객체는 원본 엔티티를 상속받은 객체이므로 타입 체크시에 유의해야한다.
- 영속성 컨텍스트에 이미 데이터가 있으면 DB호출하지않고 eg.getReference()로도 실제 엔티티가 반환된다.
- 준영속 상태의 프록시를 초기화하면 LazyInitializationException 예외가 발생한다.
프록시 확인
: PersistenceUnitUtil.isLoaded(Object entity) 메소드를 사용하면 프록시 인스턴스의 초기화 여부를 확인할 수 있다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("get");
EntityManager em = emf.createEntityManager();
boolean isLoad = em.getEntityManagerFactory().getPersistenceUnitUtil().isLoaded(entity);
// or emf.getPersistenceUnitUtil().isLoaded(entity);프록시 객체 초기화
: JPA 표준에는 프록시 초기화 메소드가 없고, 초기화 여부만 확인할 수 있다. 초기화는 하이버네이트의 initialize() 메소드를 사용하여 프록시를 강제로 초기화할 수 있다.
class OrderService {
@Transactional
public Order findOrder(Long id) {
Order order = orderRepository.findOrder(id);
order.getMember().getName(); // 프록시 객체를 강제로 초기화한다.
return order;
}
}- order.getMember()까지만 호출하면, 단순히 프록시 객체만 반환하고, 실제로 엔티티가 호출(getName())될 때 프록시가 초기화된다.
- JPA 표준에는 프록시 초기화 메소드가 없으며, 초기화 여부만 확인할 수 있다. 대신 하이버네이트를 사용하면 initialize() 메소드를 사용하여 프록시를 강제로 초기화할 수 있다.
- 초기화 여부 확인
PersistenceUnitUtil persistenceUnitUtil = em.getEntityManagerFactory().getPersistenceUnitUtil();
boolean isLoaded = persistenceUnitUtil.isLoaded(order.getMember()); // 초기화여부프록시를 초기화하는 역할을 서비스 계층이 담당하면 뷰가 필요한 엔티티에 따라서 서비스 계층의 로직을 변경해야하고, 계층간 의존관계 및 영역침범하는 상황이 생긴다. 이 문제점을 해결하기 위해 새로운 계층을 추가하는데, 이 역할을 해주는 계층이 FACADE 계층이다.
FACADE 계층
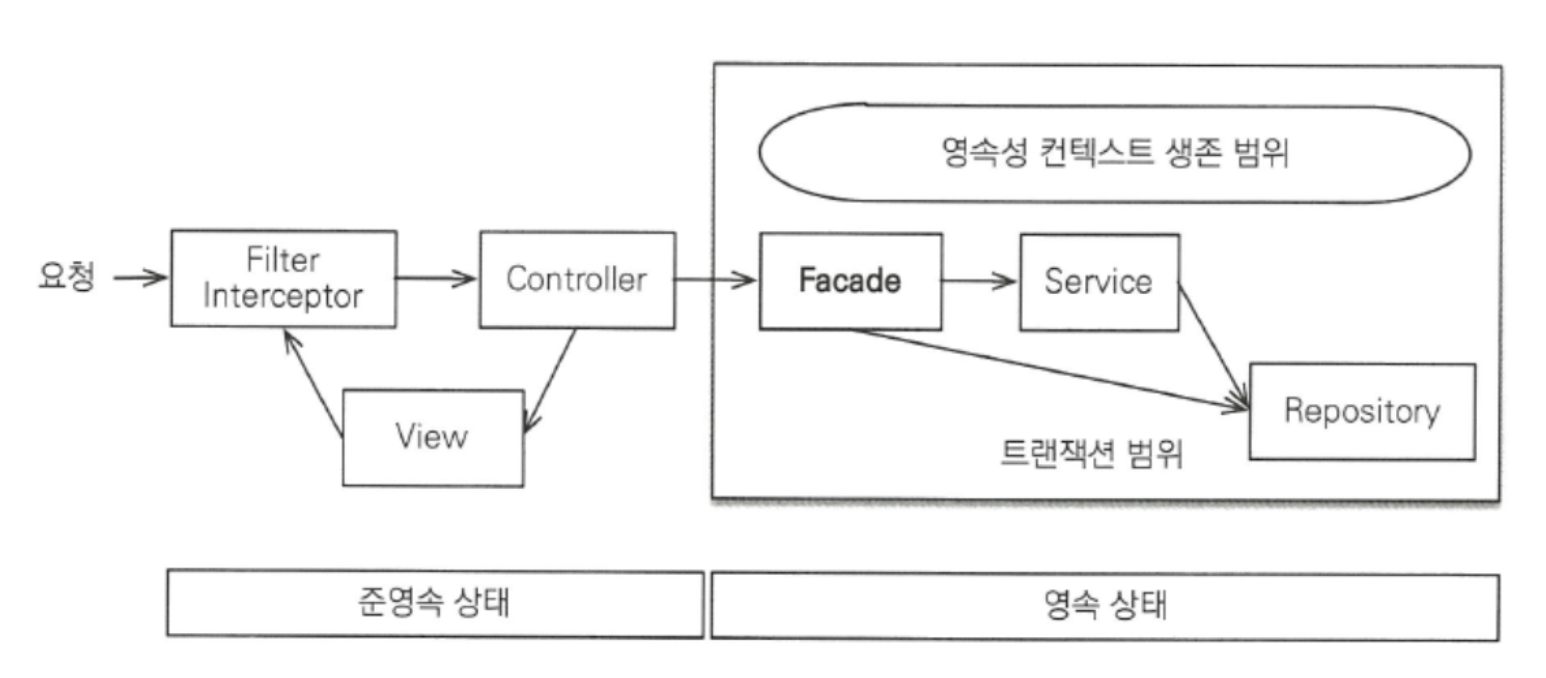
뷰를 위한 프록시 초기화는 FACADE라는 계층을 추가하여 담당한다. (JPA를 사용한 프록시 초기화는 프리젠테이션영역과 서비스영역의 경계에 서있어서 애매하다)
- 프록시를 초기화하려면 영속성 컨텍스트가 필요하기때문에 FACADE에서 트랜잭션을 시작해야 한다.
- FACADE 계층의 역할과 특징
- 프리젠테이션 계층과 도메인 모델 계층 간의 논리적 의존성을 분리
- 프리젠테이션 계층에서 필요한 프록시 객체를 초기화
- 서비스 계층을 호출해서 비즈니스 로직을 실행한다
- 리포지토리를 직접 호출해서 뷰가 요구하는 엔티티를 찾는다
- FACADE 예제
@Service // 영속성 컨텍스트를 사용해야하므로, 서비스 계층에 포함시킨다.
public class OrderFacade {
private final OrderService orderService;
@Autowired
public OrderFacade(OrderService orderService) { // ConStructor
this.orderService = orderService;
}
public Order findOrder(String id) {
Order order = orderService.findOrder(id);
// 프리젠테이션 계층이 필요한 프록시 객체를 강제로 초기화한다.
order.getMember().getName();
return order;
}
}즉시 로딩과 지연 로딩
프록시에서는 지연 로딩을 사용한다고 했다. 그렇다면 즉시 로딩과 지연 로딩은 무엇인지 알아보자.
우선, 연관관계 어노테이션에 fetch속성을 통하여옵션을 지정할 수 있다.
- 즉시 로딩: 엔티티를 조회할 때 연관된 엔티티도 함께 조회한다
- find() 호출시 연관된 객체도 함께 조회한다
- 설정 방법: @ManyToOne(fetch = FetchType.EAGER)
- 즉시 로딩사용시, JPA는 최적화하기 위해 조인쿼리를 사용한다.
- 지연 로딩: 연관된 엔티티를 실제 사용할 떄 조회한다.
- user.getGroup().getGroupName() 처럼 실제 사용하는 시점에 JPA가 SQL을 실행하여 엔티티를 조회한다.
- 설정 방법: @ManyToOne(fetch = FetchType.LAZY)
- 실제 조회하는 시점에 SQL을 실행하므로, USER과 GROUP을 각각 조회하는 경우, 즉시 로딩처럼 조인쿼리가 아닌 각각의 쿼리를 실행한다.
- 컬렉션 래퍼: 하이버네이트는 엔티티를 영속 상태로 만들 때 엔티티에 컬렉션이 있으면 컬렉션을 추적하고 관리할 목적으로 원본 컬렉션을 하이버네이트가 제공하는 내장 컬렉션으로 변경해주는 것 (org.hibernate.collection.internal.PersistentBag)
엔티티를 지연로딩하면 프록시 객체를 사용해서 지연 로딩을 수행하지만, 컬렉션은 컬렉션 래퍼가 지연로딩을 처리해주어 프록시 역할을 하므로 결국 프록시이다.
JPA 기본 fetch 전략
- 추천하는 방법은 모든 연관관계에 지연 로딩을 사용하는 것이다. (성능측면에서 좋고, 유지보수도 까다롭지 않고, 가장 객체 지향적인 방법이기 때문이라 생각이 됨)
- 컬렉션을 두개 이상 즉시 로딩하는 것은 권장하지 않는다. 컬렉션은 결국 1:N 조인형태로 성립이 되는데, 두 테이블과 1:N으로 조인이 된다면, (N x N)이 되면서 너무 많은 데이터가 조회될 수 있으며, 애플리케이션 성능이 저하될 수 있다.
- 컬렉션 즉시로딩은 항상 외부조인(LEFT OUTER JOIN)을 사용한다. NULL이 허용되고, 내부조인(INNER JOIN)으로 조회를한다면 조회가 되지 않는다. 회원이 하나도 없는 그룹을 조회할 때 그룹까지 조회되지 않는 문제가 생길 수 있다.
| (!) NULL 제약조건과 JPA 조인 전략 JPA는 기본적으로 NULL이 허용되는 상황을 고려하여 LEFT OUTER JOIN을 사용한다. 하지만 성능적인 부분을 고려한다면, 내부조인(INNER JOIN)이 더 효율적이다. 따라서 내부조인을 사용하게 하려면 NOT NULL 제약조건으로 값이 있는 것을 보장해주면 된다. @JoinColumn(name="USER_ID", nullable = false) // nullable = false로 NOT NULL 제약조건이 있음을 JPA에게 알려준다. => JPA는 선택적인 관계(NULL 허용)이면 외부조인(LEFT OUTER JOIN)을, 필수 관계(NOT NULL)이면 내부조인을 사용한다. |
영속성 전이(CASCADE)
JPA에서 엔티티를 저장할 때 연관된 모든 엔티티는 영속 상태여야 한다. 부모 엔티티와 자식 엔티티가 있다고했을때, 두 엔티티 모두 영속 상태로 만들어야한다.
@Entity
public class Parent {
@Id
@GeneratedValue
private Long id;
@OneToMany(mappedBy = "parent")
private List<Child> children = new ArrayList<Child>();
}
@Entity
public class Child {
@Id
@GeneratedValue
private Long id;
@ManyToOne
private Parent parent;
}
public static main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("cascade_test");
EntityManager em = emf.createEntityManager();
// 부모 저장
Parent parent = new Parent();
em.persist(parent);
// 자식1 저장
Child child1 = new Child();
child1.setParent(parent); // 자식 -> 부모 연관관계 설정
parent.getChildren().add(child1); // 부모 -> 자식
em.persist(child1);
// 자식2 저장
Child child2 = new Child();
child2.setParent(parent); // 자식 -> 부모 연관관계 설정
parent.getChildren().add(child2); // 부모 -> 자식
em.persist(child2);
}이 코드에서 영속성 전이를 사용한다면, 부모만 영속 상태로 만들면 연관된 자식까지 한번에 영속성 상태로 만들 수 있다.
// 영속성전이의 사용
@OneToMany(mappedBy = "parent", cascade = CascadeType.PERSIST)
private List<Child> children = new ArrayList<Child>();
// 영속성전이(CASCADE) 여러 속성 적용
// @OneToMany(mappedBy = "parent", cascade = {CascadeType.PERSIST, CascadeType.REMOVE})
/*
* CascadeType enum 코드
* ALL: 모두 적용
* PERSIST: 영속
* MERGE: 병합
* REMOVE: 삭제
* REFRESH: refresh 수행시
* DETACH: detach() 수행시
*/
// 적용예시
public static main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("cascade_test");
EntityManager em = emf.createEntityManager();
// 부모 저장
Parent parent = new Parent();
Child child1 = new Child();
Child child2 = new Child();
child1.setParent(parent);
child2.setParent(parent);
parent.getChildren().add(child1);
parent.getChildren().add(child2);
em.persist(parent); // 한번의 부모 저장으로 자식까지 영속상태로 만든다.
}이는 연관관계를 매핑하는 것과는 관련이 없으며, 단지 엔티티를 영속화할 때 연관된 엔티티도 같이 영속화하는 편리함을 제공할 뿐이다.
고아객체(ORPHAN)
: 부모 엔티티와 연관관계가 끊어진 자식 엔티티를 자동으로 삭제하는 기능.
// 고아객체 orphanRemoval옵션 설정
@OneToMany(mappedBy = "parent", orphanRemoval = true)
private List<Child> children = new ArrayList<Child>();
Parent parent1 = em.find(Parent.class, "1");
parent1.getChildren().remove(0); // orphanRemoval이 true일때, 자식 객체가 끊어지면서 DELETE 쿼리가 나간다.
parent1.getChildren().clear(); // 마찬가지로 모든 자식 객체가 제거되고, DELETE 쿼리가 나간다.- 고아객체 제거는 참조가 제거된 엔티티는 다른 곳에서 참조하지 않는 객체로 보고 삭제하는 기능이다. 따라서 삭제한 엔티티를 다른 곳에서 참조한다면 문제가 발생할 수 있다. 그렇기 때문에 @OneToOne, @OneToMany에서만 사용이 가능하다.
컬렉션
JPA는 자바에서 기본으로 제공하는 컬렉션 인터페이스를 지원한다. @OneToMany, @ManyToMany를 사용해서 일대다, 다대다 엔티티 관계를 매핑하거나 @ElementCollection을 사용해서 값 타입을 하나 이상 보관할 때 사용한다.
@OneToMany
@JoinColumn
private Collection<UserEntity> users = new ArrayList<UserEntity>();
// 하이버네이트의 특징때문에 컬렉션 사용시, 즉시 초기화해서 사용하는 것을 권장
// --- List
@OneToMany
@JoinColumn
private List<UserEntity> users = new ArrayList<UserEntity>();
// --- Set
@OntToMany
@JoinColumn
private Set<Child> childs = new HashSet<Child>();
// --- List + @OrderColumn
@OneToMany(mappedBy = "board")
@OrderCOlumn(name = "POSITION")
private List<Comment> comments = new ArrayList<Comment>();ArrayList 타입이었던 컬렉션이 엔티티를 영속 상태로 만든 직후에 하이버네이트가 제공하는 PersistentBag 타입으로 변경한다. 하이버네이트는 컬렉션을 효율적으로 관리하기 위해 엔티티를 영속 상태로 만들 때 원본 컬렉션을 감싸고 있는 내장 컬렉션을 생성해서 이 내장 컬렉션을 사용하도록 참조를 변경한다.
| 컬렉션 인터페이스 | 내장 컬렉션 | 중복허용 | 순서보관 |
| Collection, List | PersistentBag | O | X |
| 엔티티를 추가할 때 중복된 엔티티가 있는지 비교하지 않고 단순하게 저장만한다. => 엔티티를 추가해도 지연 로딩된 컬렉션을 초기화하지 않음 | |||
| Set | PersistentSet | X | X |
| 엔티티를 추가할 때 중복된 엔티티가 있는지 비교해야한다. => 엔티티를 추가할 때 지연 로딩된 컬렉션을 초기화함 | |||
| List + @OrderColumn | PersistentList | O | O |
| 데이터베이스에 순서 값을 저장해서 조회할 때 사용. 순서가 있는 컬렉션은 데이터베이스에 순서 값도 함께 관리하는데, 단점이 많아서 실무에서 잘 사용하지 않는다. - 연관관계에 의한 POSITION관련, List의 변경 등의 상황에서 추가 UPDATE 쿼리가 발생하여 성능이슈 발생 - 중간에 POSITION 값이 없으면 조회한 List에는 null이 보관되며, 순회할 때 NPE가 발생할 수 있다. |
|||
연관관계에서 사용하는 추가 어노테이션
- @OrderBy
: 데이터베이스의 ORDER BY절처럼 컬렉션을 정렬할 수 있다. 모든 컬렉션에 사용할 수 있다.
(DB 컬럼값이 아닌, JPQL의 대상처럼 엔티티의 필드를 대상으로함에 유의할 것)
@OneToMany(mappedBy = "team")
@OrderBy("name desc, id asc")
private Set<UserEntity> users = new HashSet<UserEntity>();
- @Converter
: 엔티티의 데이터를 변환해서 데이터베이스에 저장해준다.
(예를들어 true, false를 의도적으로 DB에 VARCHAR필드에 저장하고 싶은 경우)
@Entity
public class UserEntity {
@Id
private String id;
private String name;
@Convert(converter=UserConverter.class)
private boolean vip;
// ...
}
@Converter
public class UserConverter implements AttributeConverter<Boolean, String> {
@Override
public String convertToDatabaseColumn(Boolean attribute) {
return (attribute != null && attribute) ? "Y" : "N";
}
@Override
public Boolean convertToEntityAttribute(String dbData) {
return "Y".equals(dbData);
}
}- 컨버터 클래스는 @Converter 어노테이션을 사용하고, AttributeConverter 인터페이스를 구현해야한다.
- convertToDatabaseColumn() : 엔티티의 데이터를 데이터베이스 컬럼에 저장할 데이터로 변환한다.
- convertToEntityAttribute() : 데이터베이스에서 조회한 컬럼 데이터를 엔티티의 데이터로 변환한다.
- 예제는 필드에 컨버터 클래스를 적용했지만, 클래스 레벨에도 설정이 가능하다. 이때에는 attributeName 속성을 써서 필드를 지정해줘야 한다. (@Convert(converter = UserConverter.class, attributeName = "vip")
참고자료
- 서적 - 자바 ORM 표준 JPA 프로그래밍 제 5장, 6장, 8장, 14장 - 김영한 지음
'SpringFramework > JPA' 카테고리의 다른 글
| JPA - 값타입 (0) | 2021.11.16 |
|---|---|
| JPA - 연관관계 고급매핑 (0) | 2021.11.15 |
| JPA - 엔티티 매핑 (0) | 2021.11.12 |
| JPA - 영속성 컨텍스트 (0) | 2021.11.03 |
| JPA - 기본 개념 및 내용정리 (0) | 2021.02.05 |