로드밸런서는 실제 웹서비스를 운영하면서 많이 사용하는 컴퓨터 네트워크 기술이다. 로드밸런서를 사용하지 않는 서비스는 거의 없을 정도로 중요한 개념이며, 안정적으로 서비스를 운영할 수 있는 방법이다.
로드밸런서란?
서버에 들어오는 대량의 부하(트래픽)을 분산해주는 장치, 또는 기술을 말한다. 클라이언트와 서버의 중간에 위치하고 있으며 한쪽으로 부하가 집중되지 않도록 트래픽을 관리하고 병럴처리를 통해 각 서버가 최적의 퍼포먼스를 낼 수 있도록 해준다. 웹사이트, 실시간 채팅서버, FTP, DNS 서버 등에 적용하여 사용되고 있다. 인터넷 서비스를 제공할때 로드밸런서는 소프트웨어(apache 등)를 이용한 부하분산이 적용되며, 중간에서 실제 서비스하는 서버와 클라이언트를 포트를 이용하여 중개를 하고있다. 사용자는 이를 알아채지 못하기때문에 보안측면에서 내부 네트워크 구조를 숨길 수 있기때문에 크래킹을 막을 수 있다.
로드밸런서는, 서버를 확장할때 Scale Out 방식으로 하는 경우에 반드시 필요하다. 혼자서 트래픽을 담당하다가, 동일한 서버가 추가되었다면, 그 트래픽을 분산해서 처리하도록 해주어야하기 때문이다.

사진출처: https://thebook.io/007046/ch06/02/
로드밸런서의 다양한 알고리즘
1] 라운드로빈 방식(Round Robin Method)
서버에 들어온 요청을 순서대로 돌아가며 배정하는 방식이다. N대의 서버가 동일한 스펙을 가지고 있고, 서버와의 연결이 오래 지속되지 않는 경우에 좋다.
2] 가중 라운드로빈 방식 (Weighted Round Robin Method)
각각 서버마다 가중치를 부여하여 가중치가 높은 서버에게 우선적으로 요청을 배분하는 방식이다. 서버의 스펙이 다른경우에 사용하며, 일반적으로 스펙이좋은 서버에게 가중치를 부여한다.
3] IP 해시 방식 (IP Hash Method)
클라이언트의 IP 주소에 따라 특정 서버로 매핑하여 요청을 처리하는 방식이다. 사용자의 IP를 해싱하여 분배하므로 동일한 서버로 연결시켜준다.
4] 최소 연결 방식 (Least Connection Method)
요청이 들어온 시점에 가장 적은 연결상태를 보이는 서버에 우선적으로 요청을 배분하는 방식이다. 자주 세션이 길어지거나, 서버에 분배된 트래픽들이 일정하지 않은 경우에 적합한 방식이다.
5] 최소 리스폰타임 (Least Response Time Method)
서버의 현재 연결 상태와 응답시간에 따라 요청을 배분하는 방식이다. 기준은 가장 적은 연결 상태와 가장 짧은 응답시간을 보이는 서버에 우선적으로 배분한다.
(!) 더 많은 로드밸런서 알고리즘 확인 : https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html-single/load_balancer_administration/index#s2-lvs-sched-VSA
NLB VS ALB
부하 분산에는 L4 로드밸런서와 L7 로드밸런서가 가장 많이 활용된다. L4 단계에서부터 IP, Port 정보를 바탕으로 요청을 분산하는 것이 가능하기 때문이다. 한대의 서버에 각기 다른 포트 번호를 부여하여 다수의 서버 프로그램을 운영하는 경우라면, L4 이상의 로드밸런서를 사용해야할 것이다. 따라서 IP/Port나 MAC주소, 전송 프로토콜에 따라 트래픽을 나누는 것이 가능하다. 이러한 방식을 NLB (Network Load Balancer)라고 한다.
반면, L7 로드밸런서는 어플리케이션 계층, HTTP(S), FTP, SMTP(메일전송프로토콜)에서 요청을 분산하게 되는데, 헤더나 쿠키, URL에 따라 분산하는게 가능하기 때문에 훨씬 더 섬세한 라우팅이 가능하다. 또한 비정상적인 트래픽(DDos 등)을 필터링할 수도 있어서 네트워크 보안에서 이점을 얻을 수 있으며, 서비스를 조금 더 안정성 있게 운영할 수 있게 된다. 이러한 방식을 ALB (Application Load Balancer)라고 한다.
최근에는 Kubernetes를 통해 서비스 환경을 구축하고 L7 로드밸런싱을 구성하여 MSA로 서비스를 나누는 방법이 굉장히 인기가 많다고 한다. 나도 최근에 쿠버네티스 서적을 읽고있는 중인데, 로드밸런싱 구축하는 방법은 별도로 정리해나가고 있다.
Kubernetes 로드밸런서: https://xggames.tistory.com/69
(!) 네트워크 7계층 위키: https://ko.wikipedia.org/wiki/OSI_%EB%AA%A8%ED%98%95
로드밸런서를 사용시, 다중 서버 환경에서의 세션(Session)관리방법
면접을 보면서 면접관님께서 하셨던 질문중 하나였는데, 개발만했지.. 머릿속에 제대로 정리가 안되어있는 것 같아서 추가로 정리하고자 한다.
다중 서버 환경에서는 웹서비스를 할때 Session을 어떻게 구성할까?

Session은 서버 1대당 하나의 저장소가 형성된다. 여기에서 웹서버를 로드밸런서를 통해 서비스를 제공한다면 세션 정합성 이슈가 발생할 것이다. WAS1번서버에서 사용자가 로그인을 해서 세션정보를 취득했다고 했을때, 이 사용자가 WAS1이아닌 다른 서버로 요청을 보낸다면 세션정보가 없기때문에 다시 로그인을 해야하는 상황이 올 것이다.
이러한 문제를 해결할 방법을 알아보자.
1] Sticky Session 방식
고정된 세션 방식이다. 로드밸런서는 요청을 받으면 쿠키가 존재하는지 확인하여 해당 요청이 쿠키에 지정된 서버로 전송시켜준다. WAS1번 서버에서 세션 정보를 취득했다면, 해당 요청은 계속 WAS1번서버로만 갈 것이다. 쿠키가 없으면, 기존 로드밸런서에 설정된 알고리즘 기반으로 요청을 보낸다.
Sticky Session방식은 세션 정합성 이슈는 해결되지만, 특정 사용자는 특정 서버로만 이동하는 문제점을 가지고 있기 때문에, 하나의 서버에 트래픽이 집중되어도 이를 완전하게 분산할 수는 없다. 그리고 서버가 부하를 일으켜 장애가 발생한다면, 해당 세션을 가진 사용자들은 다른 WAS서버로 가서 재로그인을 해야하는 불편함이 생길 것이다.
2] All-to-all Session Replication 방식
각 WAS서버의 세션저장소에 변경되는 내용이 발생시, 다른 서버에 복제를 해주는 방법이다. 다른 서버에 요청이 가더라도 세션 정합성 이슈가 발생하지 않게 된다. 특정 서버에서 장애가 발생하더라도 서비스는 중단되지 않게 된다. 하지만 이 방식에는 명확하게 단점이 존재한다. 모든 서버가 동일한 세션 객체를 가져야 하기 때문에 많은 메모리가 필요하다. (사용자가 10명, 서버가 4대라면, 10x4 = 40개) 그리고 세션정보를 다른 서버에 복제해주어야 하기 때문에, 서버 수에 비례하여 네트워크 트래픽이 증가하여 성능 저하 이슈가 발생한다.
All-to-all Session Replication 방식은, 소규모 환경에서는 나쁘지 않을 수 있으나(그 이유는 소규모환경에서 굳이 별도의 세션저장소를 두어서 운영했을 경우, 비용이 더 발생할 수 있을 것 같다) 대규모 환경에서는 추천하지 않는 방법이다.
3] Primary-Secondary Session Replication 방식
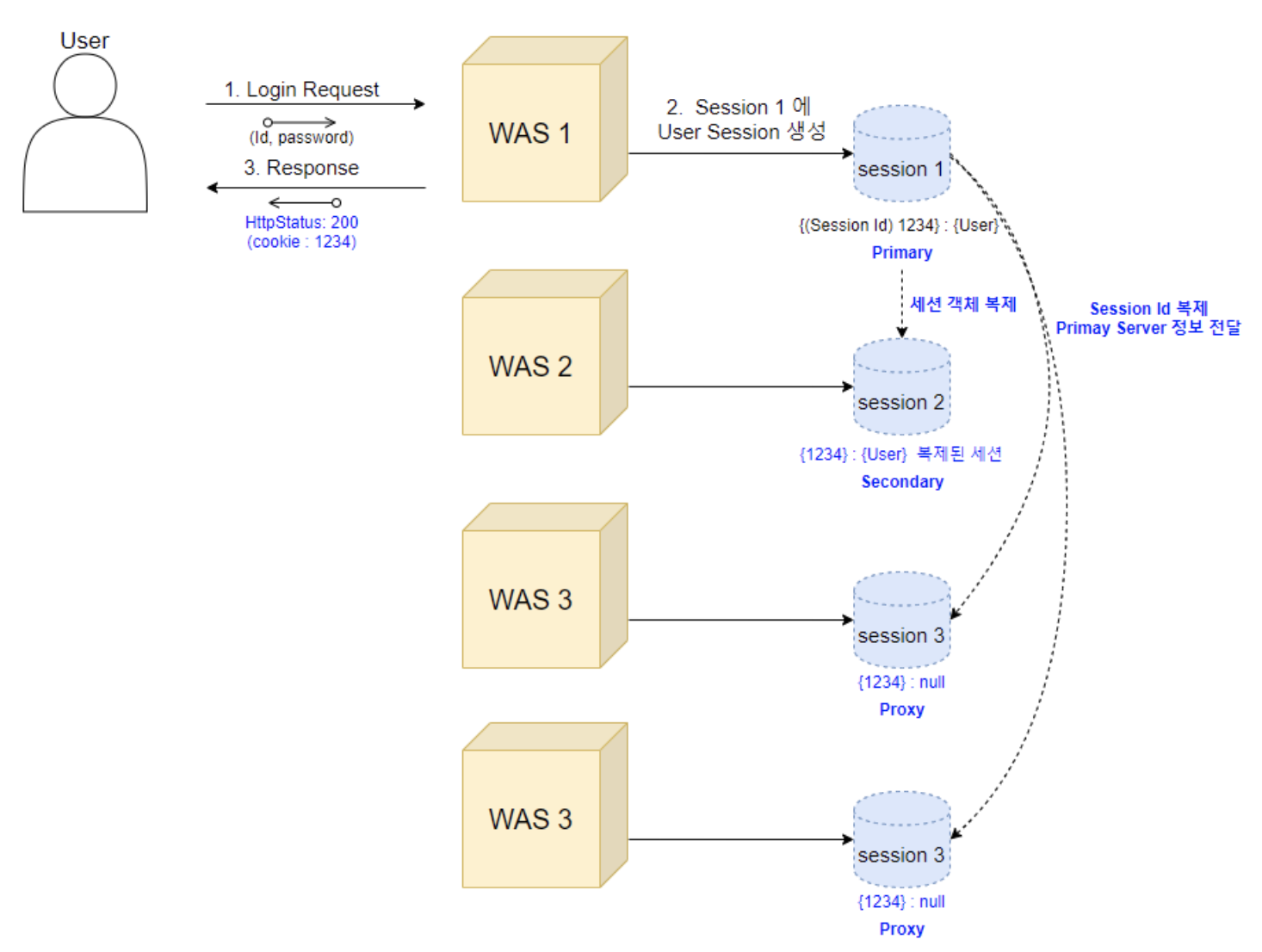
All-to-All 보다 조금 개선된 버전이며 세션저장소를 Primary, Secondary(BackUp), Proxy로 나누어서 운영하는 방식이다. Proxy 세션저장소에 해당하는 서버에 요청이 들어오면, Primary에서 세션 정보를 전달해준다. 세션을 복제하는데 사용되는 시간을 줄일 수 있고 메모리사용이 줄어들어서 확실히 전체 복사하는 것보다는 좋은 방법이다. 하지만 여전히 대규모 환경에서는 성능저하가 이루어질 수 있다.
4] Session Storage 구성
아예 별도의 세션저장소(Session Storage)를 구축하는 방법이다.
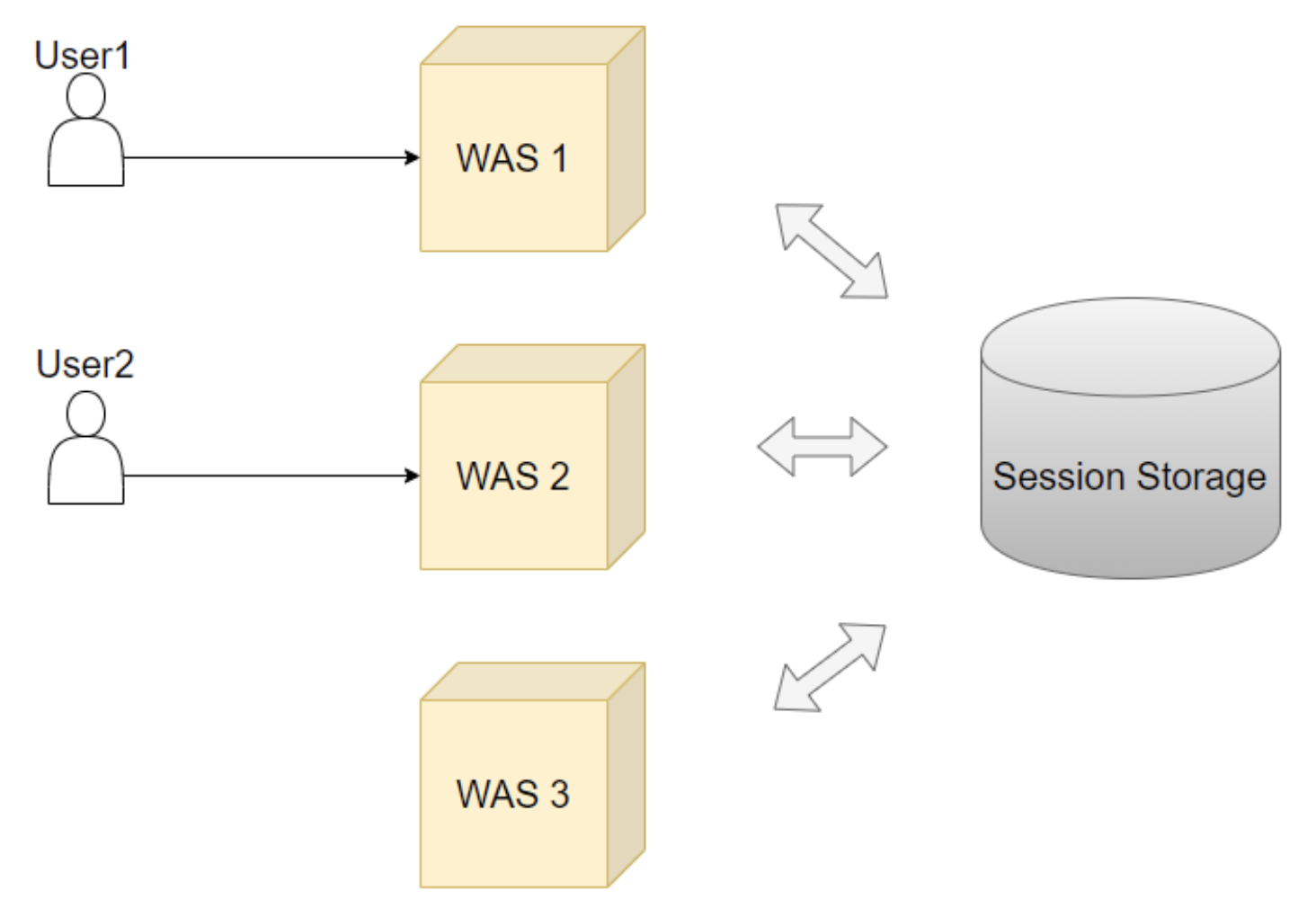
세션 저장소가 분리되면, 서버 Scale Out이 크게 늘어나도 세션 스토리지에 대한 정보만 각 서버에서 알고있다면 세션 공유가 가능하다. Sticky Session 방식처럼 트래픽이 비정상적으로 몰리지 않을 것이며, 로드밸런서의 어떤 알고리즘을 사용하더라도 문제가 없어진다. 특정 WAS 서버 장애가 발생하더라도, 문제없이 서비스를 운영할 수 있기때문에 가용성도 확보가 된다. 단, 세션저장소 자체 서버의 장애가 발생하면 모든 세션 이용이 불가능하기때문에 가용성 확보를 위해 동일한 세션 저장소를 복제해놓아야 할 것이다.
(세션 저장소로 많이 활용되고 있는 방법으로 in-memory 기반의 Redis와 Memcached 등이 있다)
참고자료
= https://ko.wikipedia.org/wiki/%EB%B6%80%ED%95%98%EB%B6%84%EC%82%B0
= https://m.post.naver.com/viewer/postView.naver?volumeNo=27046347&memberNo=2521903
= https://hyuntaeknote.tistory.com/6
'Server & Infra' 카테고리의 다른 글
| Server - DNS란 무엇인가 (0) | 2022.03.23 |
|---|---|
| Server - WS(웹서버)와 WAS(웹어플리케이션서버)의 차이 (0) | 2022.03.10 |
| Server - ubuntu에 mariaDB 설치하기 (0) | 2021.10.20 |
| Server - 리눅스(ubuntu)에서 계정생성 ~ sudo권한 추가까지 한번에 하기 (0) | 2020.03.21 |
| Server - ubuntu에서 필요한 것들 설치명령어 (0) | 2020.03.21 |