DataBase에서의 Replication이란?
복제를 의미하며, 2대 이상의 DBMS를 나누어서 데이터를 저장하는 방식이다. master - slave 방식을 주로 사용하며 master - master, 다중 slave 방식으로도 사용한다.
어플리케이션 서버와 데이터베이스간에 기본적으로 아래와같이 심플하게 구성을 한다고 해보자.

보통 개발환경에서는 단순한 모델을 가지고 구축을 진행한다. 하지만 실제 운영환경에서 트래픽이 증가하여 데이터베이스가 많은 Query를 처리를 하게되면, 부하가 걸릴 것이다. 이 때 Repliaction을 진행하여 분리한다면 데이터베이스의 부하분산 처리 효과를 가져갈 수 있다.
Master와 Slave

위의 그림처럼 Master DB와 Slave DB를 나누어서 분산처리 하는 모델로 변경하였다.
Replication은 비동기방식으로 데이터를 복제한다.
Master는 주로 Insert, Update, Delete Query를 담당한다. 그리고 데이터 변경이 일어날 때, binary log에 기록하고, Slave서버에 전달해준다.
(!) binary log? mysql(혹은 mariaDB)에서 발생하는 모든 내역들이 기록되는 파일을 의미. 이 파일은 기본적으로 비활성화상태인데, replication 사용시, 활성화시켜주어야 한다.
Slave는 Select Query를 담당한다. Master에서 생성하는 binary log파일을 I/O Thread를 통해 Master에 요청하여 가져와서 데이터 복제를 진행한다. 실제 서비스에서 SELECT의 비중이 높은 경우가 많으므로 분산 효과가 있다.
Repliaction의 장점
- 부하 분산 효과가 있다. (SELECT)
- 장애 발생으로 인하여 데이터 손실 발생시, 데이터를 복제하여 동기화하기 떄문에, 복구가 가능하다. (장애발생시 Slave서버를 Master서버로 승격이 가능하기 때문)
- Master서버에 영향을 주지않으면서 데이터 분석이 가능하다.
Replication의 동작 과정
복제 방식
1] Statement Based: SQL문장을 복사하여 진행
2] Row Based: SQL에 따라 변경된 Row만 기록하는 방식
3] Mixed: 기본적으로 Statement Based방식으로 진행하면서, 필요에 따라 Row Based를 사용한다.
복제 Flow
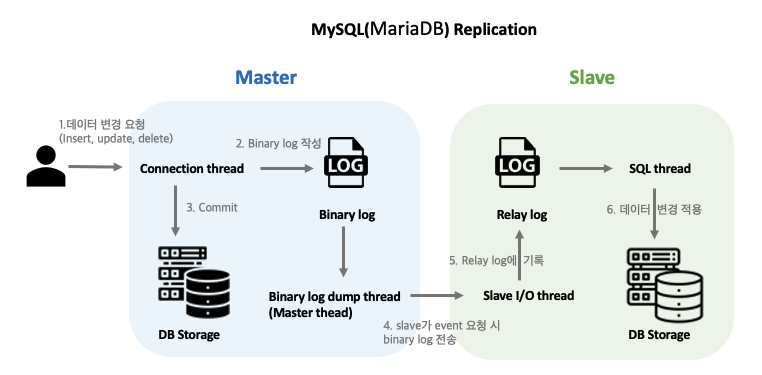
Replication 사용시, 주의해야할 내용들
- Database는 구성환경이 같아야 한다. (DB version의 경우, Slave가 Master보다 상위버전이어야함)
- Master -> Slave 순서로 동작처리를 진행해야 한다. (binary log파일 기록 -> 복제 진행)
Replication 실행 예제
(테스트 및 작성예정)
참고자료
= https://server-talk.tistory.com/240
= https://danidani-de.tistory.com/28
= https://nesoy.github.io/articles/2018-02/Database-Replication
'DataBase' 카테고리의 다른 글
| DB - INSERT INTO VS REPLACE INTO (0) | 2022.05.24 |
|---|---|
| DB - 복합키 순서 (0) | 2022.04.05 |
| DB - 정규화(Normalization) (0) | 2022.03.17 |
| DB - 실행계획(explain) 보는방법 (0) | 2022.03.13 |
| DB - Bulk Insert (0) | 2022.03.13 |